Buy Potato Bake Potato: From Local Project to Cloud-Native Transformation
"Buy Potato Bake Potato" began as a senior project for college – it was a recipe recommendation website, built on React, Python, and Mariadb. In its initial incarnation, the entire application resided in a single GitHub repository and was designed as a monolithic application that ran locally on a single computer.
My goal was to evolve this relatively simple, local application to a globally available, high-performance, highly scalable architecture by leveraging cloud-native technologies, microservices, and current best-practice design principles.
At a high level, I wanted to:
-
Refactor the code base to enable a distributed microservices implementation
-
Utilize containers to simplify code packaging, testing, and deployment
-
Use public cloud providers and Kubernetes to provide global availability and scalability
-
Utilize Continuous Integration/Continuous Deployment (CI/CD) pipelines and DevOps practices to automate not only the deployment and testing of the code itself but also the cloud network infrastructure.
The intent of this article is to provide an overview of the process of transforming the application to achieve those goals. In future articles, I plan to cover the details of specific aspects of the project.
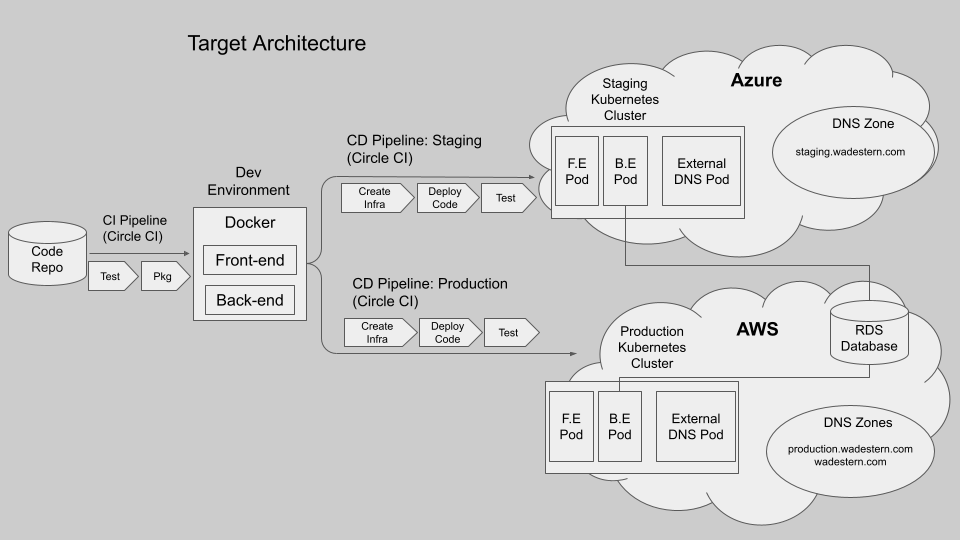
1. Refactoring the code base to enable a distributed microservices implementation.
The initial implementation of the "Buy Potato Bake Potato" application was entirely local and stored in a single GitHub repository. However, this setup posed several limitations that hindered its scalability and deployment efficiency.
To address these limitations, I began to refactor the code by first separating the major components of the application into distinct Git repositories, to allow for more flexibility, independent versioning, and overall easier code management.
Previously, the application relied on "localhost" for communication between its components – which meant that the application components could not be distributed across different network IP addresses. To address this, I replaced all localhost references with a variable to represent the target URL – which could be set appropriately for the various environments where the application would be deployed, such as development, testing, and production environments.
Additionally, the database, originally local, was moved to Amazon Web Services' Relational Database Service (RDS). The decision to use AWS RDS was based on several factors, including the scalability, reliability, and robust features it provides. I originally tried to put my database in a persistent volume in Docker, but decided to change my approach because this solution would create a new version of the database every time I deployed it. I would have also needed to either create a permanent data store or save the data from the Kubernetes volume to prevent losing it when I shut down my Kubernetes cluster.
2. Simplifying Deployment with Containers
Once the code was refactored and the architecture could be distributed, the next step was to “containerize” the components to simplify the distribution process. The process began by creating Docker images for both the front end and back end, which were then uploaded to Docker Hub.
Docker brought several advantages – It offered high isolation, ensuring that changes within one container would not affect others, a critical aspect for both security and stability. This isolation also facilitated the decomposition of the application into microservices. Docker containers provided portability and could run in various environments, which simplified the ability to deploy the application to multiple different cloud providers. Moreover, Docker supported scalability, version control, and seamless integration with DevOps practices, which would improve resource utilization and streamline development workflows.
The Dockerfiles played a pivotal role in creating Docker images. They initiated the process by selecting appropriate base images. For the front end, the base image was "node:18.13.0," and for the back end, "python:3.10" was chosen. The files also provided an easy way to gather all relevant project files from the repositories and execute dependency installation. Finally, they exposed the specified network ports and started the application.
3. Enabling Deployment on Kubernetes and Multiple Cloud Infrastructures.
For deployment, I chose Kubernetes based on its capabilities for orchestrating containerized applications and the growing ecosystem of tools and providers. To facilitate deployment, I created four deployment files: production front end, production back end, staging front end, and staging back end.
Key Considerations for Selecting Kubernetes:
-
Multi-Cloud Compatibility: Kubernetes made it possible to deploy my application on both AWS and Azure using uniform deployment files.
-
Self-Repairing: Kubernetes automated various aspects of application management, including self-healing mechanisms that detected and replaced failed containers or nodes, ensuring operational reliability.
-
Scalability: Kubernetes allowed for seamless scalability adjustments through replica count manipulation and facilitated deployments across multiple regions, with cross-region load balancing.
-
Monitoring and Management Tools: The Kubernetes ecosystem offers an array of monitoring and management tools, including Prometheus and Grafana, enhancing operational efficiency and guaranteeing application health.
Kubernetes simplified the task of scaling. Adjusting the replica count in the deployment file was all it took to increase the number of pods. Moreover, the application's reach and availability can easily be expanded by deploying it across different servers, promoting global accessibility.
Kubernetes played a pivotal role in the cross-cloud deployability of the application. The goal was to create an infrastructure and tooling that would work on any cloud provider. To start, I selected AWS and Azure For AWS, I built the deployment around the EKSCTL CLI tool which greatly streamlined the creation and deployment of the Kubernetes clusters on AWS. There wa no analog tool for Azure, so the Azure deployment process was a bit more complex.
4. Infrastructure Changes
To better facilitate portability of the application, I made code modifications to accommodate environment-specific variables. For instance, URL configurations were adjusted based on deployment locations. In the case of an AWS deployment, the environmental variable for URLs was set to "prod.wadestern.com," while a staging deployment used "staging.wadestern.com." In the absence of such variables, the application defaulted to "localhost" to facilitate testing without deployment.
I modified the unit and staging tests for the application so that the results could be interpreted. CircleCi is able to read test results that are in XML format, so I had all of the tests give their results in an XML file.
To streamline the development process, I added essential files, including Dockerfiles for image creation, deploy files for Kubernetes deployments, and a CircleCI configuration file to define the pipeline's stages and actions.
Given my limited budget, I decided to have my pipeline create and dismantle the Kubernetes clusters every time it ran. This meant that IP addresses for the applications would be different for every deployment. This presented a challenge for DNS, as that meant that the DNS records for the application services would need to be dynamically updated every time a Kubernetes cluster was deployed. To facilitate this, I included a Kubernetes application called “External DNS” and included it in the deployments. I also split my dns domain (wadestern.com) into multiple zones so that I could more easily assign permissions to the external DNS application for managing the appropriate zone (production.wadestern.com or staging.wadestern.com). I created deployment files for both AWS and Azure for the pipeline to deploy before deploying my application so that it can create DNS records for the newly deployed application.
Conclusion
In summary, the journey of transforming "Buy Potato Bake Potato" enabled me to learn a wide range of technologies, including containers, Kubernetes, AWS, Azure, DNS, and CI/CD. By evolving the application from a simple web application to a fully scalable cloud-native platform, it can now deliver an enhanced user experience while adapting to the demands of a global audience. In the future, I would like to decompose the backend into microservices so that the application can be scaled efficiently. I would also like to create a version of the pipeline that allows me to run my backend as a serverless application. Finally, I would like to create a plan to implement blue-green deployment so that I can minimize disturbances when I roll out updates. I’m planning to cover these and other topics in future articles and blog posts on [my blog] (http://projects.wadestern.com)